Building an LLM from Scratch: From Embeddings to a GPT-Style Decoder
Why I Built This
I did not want language models to remain a black box. Instead of jumping directly into a prebuilt framework, I decomposed the architecture into five notebooks and rebuilt the decoder step by step, validating each new idea before moving to the next one.
That progression matters. It turns transformer architecture from something you can import into something you actually understand: how embeddings become context, how attention changes token interactions, and how a reusable transformer block becomes a full autoregressive language model.
Notebook Stages
5
Decoder Blocks
12
Attention Heads
4
Tokenizer Vocab
50,257
The Model-by-Model Progression
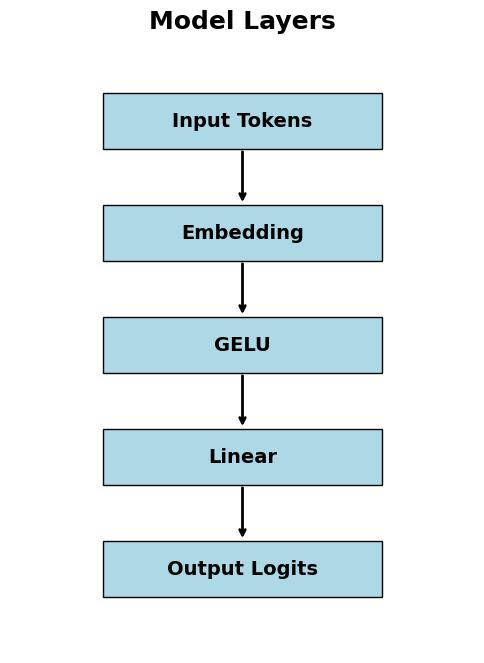
Model 1 - Minimal Language Model
The first notebook establishes the smallest useful next-token pipeline: token IDs -> embedding lookup -> GELU -> linear projection -> logits.
- - Built the training intuition around token embeddings and logits before introducing transformer complexity.
- - Used a raw PyTorch dataset and simple generation flow to make each tensor transformation inspectable.
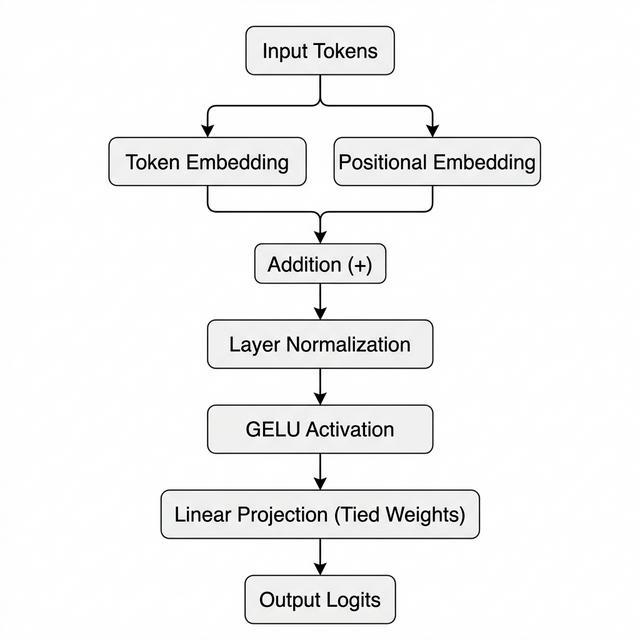
Model 2 - Position + Normalization + Weight Tying
The second notebook adds positional information, layer normalization, and a tied output head so the model starts to resemble a real decoder language model.
- - Combined token embeddings with positional embeddings to encode sequence order.
- - Introduced LayerNorm and tied the output projection back to the token embedding matrix.
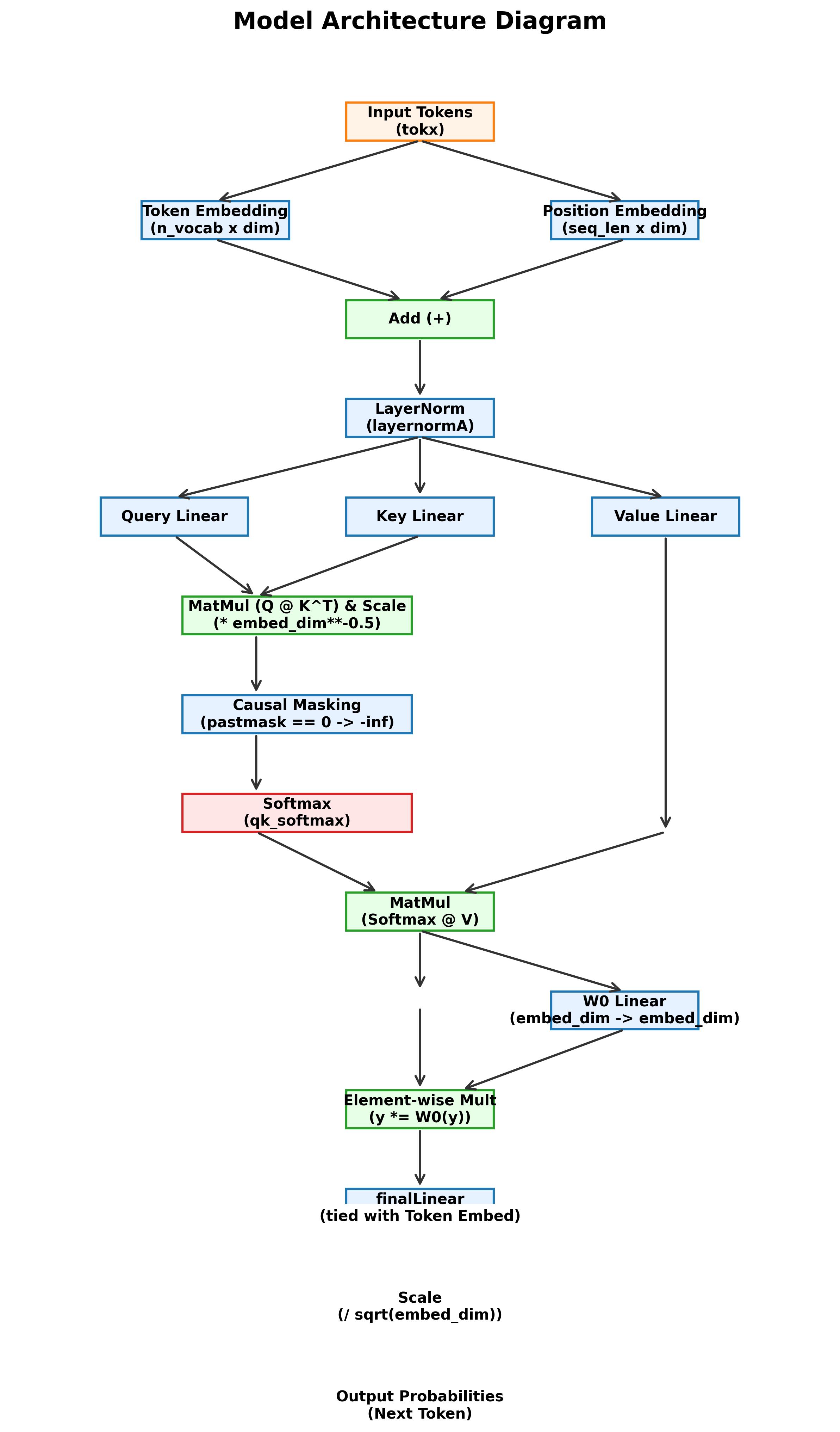
Model 3 - Attention Enters the System
The third step introduces attention, where query, key, and value projections let the model compute token relationships rather than treating each token independently.
- - Built scaled attention with causal masking so the model only attends to the past.
- - Moved from local token processing to contextual sequence reasoning.
Model 4 - Reusable Transformer Block
The fourth notebook packages attention and MLP computation into a reusable transformer block with residual paths and normalization around both sublayers.
- - Added skip connections so deeper stacks remain trainable and stable.
- - Structured the model around the same building block repeated across decoder depth.
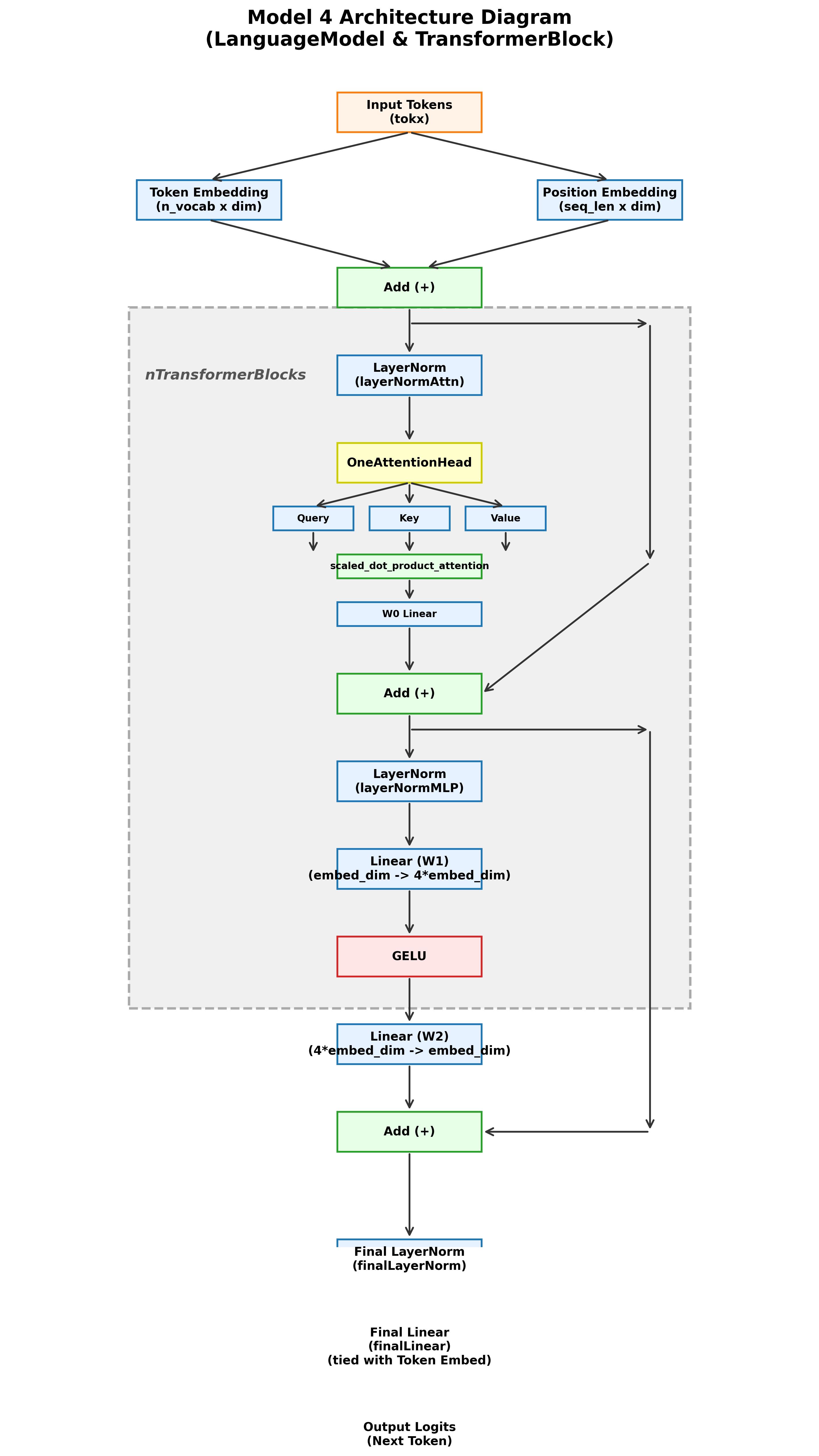
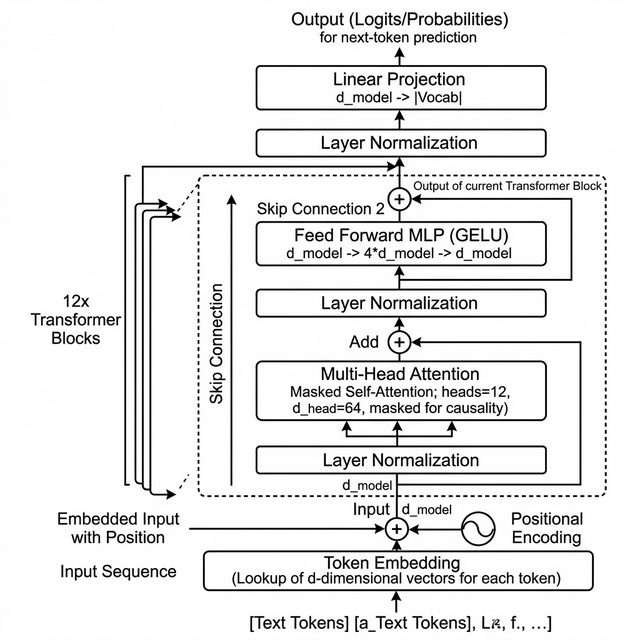
Model 5 - GPT-Style Decoder Stack
The final notebook assembles the full decoder pattern: token and position embeddings, 12 transformer blocks, final layer normalization, tied output projection, and autoregressive generation.
- - Implements multi-head causal self-attention, residual MLP layers, and next-token sampling with temperature.
- - Uses a GPT tokenizer vocabulary of 50,257 tokens with a compact, inspectable PyTorch implementation.
What the Final Notebook Implements
In the final notebook, the architecture mirrors the shape of a GPT-style decoder: token embeddings, positional embeddings, a stack of transformer blocks, final normalization, a tied output projection, and autoregressive generation over the next token.
Input tokens -> token embedding + positional embedding -> 12x [LayerNorm -> masked multi-head attention -> residual] -> 12x [LayerNorm -> MLP (GELU) -> residual] -> final LayerNorm -> tied linear projection to vocabulary logits -> temperature-based next-token sampling
The notebook code also shows the implementation details directly: `MultiHeadAttention`, `TransformerBlock`, `LanguageModel`, tied embedding weights, and a `generate()` loop that rolls the context window forward token by token.
Why This Project Matters
This project is valuable because it demonstrates architectural understanding, not just framework usage. By building the decoder in stages, I made each design decision explicit: why positional embeddings matter, why causal masking is necessary, why residual connections stabilize depth, and why tied weights are elegant and efficient.
It also gave me a much stronger mental model for the systems I build now across agentic AI, RAG, and production LLM infrastructure. Once you understand the internals, the higher-level systems become far more deliberate to design.
What I Learned
- - Building from scratch forces clarity around every tensor transformation inside a decoder.
- - Attention only becomes intuitive when you implement query, key, and value flows yourself.
- - Transformer depth is far easier to reason about once you first isolate a single reusable block.
- - Weight tying, normalization, and residual pathways feel small on paper but become central in practice.