Reclaiming Time: Why (and How) I Built Job Share Hub for Students
The Motivation
In my early student days, the hardest part of breaking into tech was not coding itself. It was the exhausting job hunt. I watched peers spend hours every day scrolling LinkedIn, filtering irrelevant posts, and manually tracking opportunities.
That time should have gone into learning, building projects, and interview prep. I wanted to automate the most tedious parts of discovery so students could reclaim time and focus.
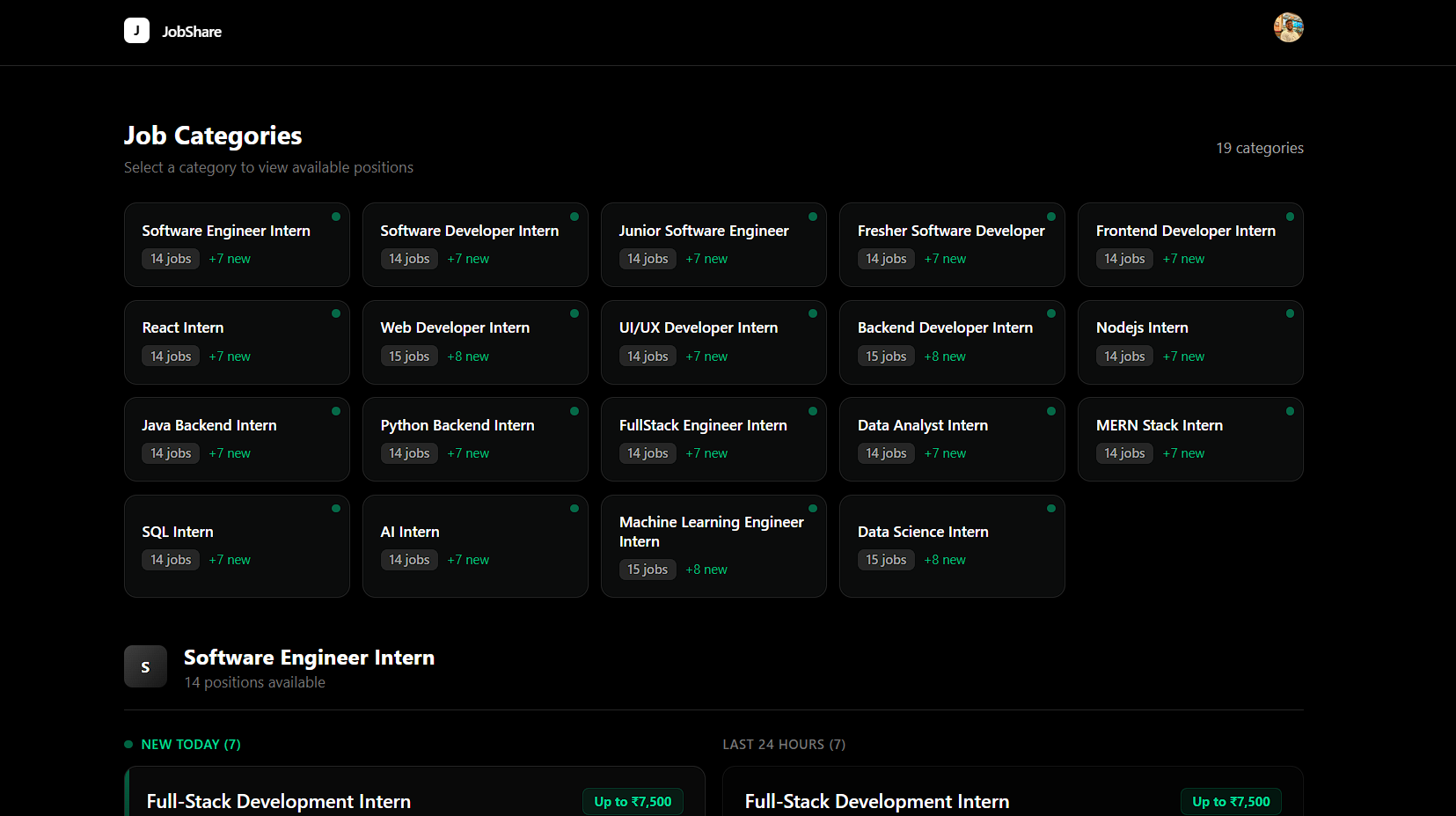
That idea became Job Share Hub: a centralized, automated platform that surfaces relevant opportunities in a clean and distraction-free interface.
Daily Active Users
60+
Time Saved
10+ hrs/week
Jobs Curated
1,000+
Maintenance
100% Automated
How I Built It
Data Engine
Python scripts such as collect_job_urls_unique.py and fetch_job_details.py use Selenium + BeautifulSoup to discover opportunities, enrich details, and remove expired listings every 24 hours.
Frontend Experience
Built with Next.js and Tailwind CSS for a fast, minimal, and student-friendly interface where the value is visible immediately after login.
Secure Access
Clerk authentication and authorization secure sessions and gate access while keeping sign-in smooth and frictionless.
A Look at Job Share Hub
Architecture: Under the Hood
1) MCP Server Core
The scraping core is built around an MCP server (linkedin_server.py) using FastMCP. This converts tools like get_job_details and search_jobs into modular callable APIs instead of a single monolithic scraper.
It manages LinkedIn access with persistent session cookies and a dual fallback strategy: try lightweight public SEO pages first, then switch to authenticated requests.Session when needed.
2) Unidirectional Data Pipeline
Discovery - collect_job_urls_unique.py
Loops through a matrix of job keywords and locations, buckets jobs by TTL (1h/24h), and performs O(1) URL deduplication using set-based logic.
Extraction - fetch_job_details.py
Consumes deduplicated URLs, fetches raw job pages, and parses DOM structures via BeautifulSoup to extract meaningful role context.
AI Enhancement - enhance_job_roles.py
Uses LangChain + Azure OpenAI with typed Pydantic output parsing to enrich listings with clean role labels, skill tags, and stipend/salary fields.
Garbage Collection - cleanup_24h.py
Prunes stale entries every 24 hours so the feed remains lightweight, current, and fully self-maintaining.
3) Frontend + Deployment Strategy
The Next.js 16 + React 19 frontend is fully decoupled from scraping. Instead of live database queries, pipeline output is compiled into static JSON files (jobs_data.json and job_details.json) consumed by the frontend from /public.
The pipeline is orchestrated through sequential scripts and Git-based publishing, enabling fast delivery to hosted environments with minimal runtime infrastructure cost.
Why This Project Matters
- - Demonstrates modern AI-native architecture with MCP-driven tooling.
- - Applies practical CS depth: O(1) deduplication, DOM parsing, and stateless JWT security.
- - Shows production tradeoff maturity: static JSON serving for low latency, low cost, and operational simplicity.
Looking Forward
Job Share Hub started from empathy for students and grew into a production-ready automation system. It keeps proving a simple idea: the best products often solve the pains your friends face every day.